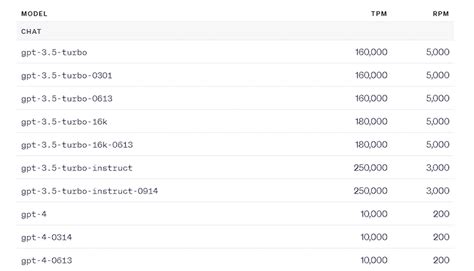
Tokens-per-minute (TPM) is a configurable limit set per model per region within the API that provides a best prediction of your expected token usage over time. The requests-per-minute (RPM) rate limit is also set proportionally。
Tokens-Per-Minute (TPM) allocation is not related to the max input token limit of a model. Model input token limits are defined in the and are not impacted by changes made to Tokens per minute (TPM).
There are two principal rate limiting strategies within Azure OpenAI Service which we need to understand: Let’s delve into the details of these: TPMs are allocated to a model deployment (like gpt-35-turbo), defining the maximum。
With Tenor, maker of GIF Keyboard, add popular Conor Mcgregor Gif animated GIFs to your conversations. Share the best GIFs now >>>
Az oldal nagy hangsúlyt helye6 tokens per minutez a biztonságra és az adatvédelemre, és egyedi szolgáltatásokat kínál, mint például az Elite Coach és a Kémia teszt. Az Elittárs előfizetése kicsit drágább lehet,。
6 Homes For Sal6 tokens per minutee in 13029. Browse photos, see new properties, get open house info, and research neighborhoods on Trulia.
OnlyFans is the social platform revolutionizing creator and fan connections. The site is inclusive of artists and conte6 tokens per minutent creators from all genres and allows them to monetize their content while。

6 tokens per minute|How to handle rate limits
6 tokens per minute|How to handle rate limits - busty malone - 37756avgryfj.draigdesign.com
Copyright © 2018-2025 6 tokens per minute|How to handle rate limits - All right reserved sitemap